Two verticals. Both are regulated. Both are complex. Both are flush with capital right now.
In March 2026 alone, Harvey raised $200 million at an $11 billion valuation, and Legora raised $550 million at $5.55 billion — a combined $750 million in legal AI in fifteen days. Healthcare AI isn’t far behind: ambient scribing has gone from nearly zero to 92% of US health systems deploying, implementing, or piloting the technology in roughly three years, and the clinical documentation AI market is projected to grow from $1 billion today to $10.5 billion by 2034.
The money is there. The adoption is real. The question that matters — the question most founders, product leaders, and investors aren’t asking clearly enough — is Which of these companies will still be standing when the generic foundation models get good enough to do what they do for free?
That’s the only question. And the answer requires mapping what layer of the intelligence supply chain each company actually owns.
The Framework: Why Verticals Change Everything
Before going into legal or healthcare specifically, one observation that applies to both: regulated industries are among the most unusual environments in the entire AI stack, and that unusualness is the source of both their opportunity and their risk.
In most software categories, the barrier to building is technical. In regulated verticals, the barriers are often institutional — licensing requirements, liability exposure, privileged data, compliance frameworks, trust relationships built over years, and procurement processes that take eighteen months to navigate. These barriers are slow and frustrating when you’re trying to get in. Once you’re in, they’re the wall that keeps competitors out.
The Supply Chain of Intelligence™ framework maps the generative AI stack across 10 layers — from raw compute (L0) through data (L1), models (L2), trust gates (L3), access and integrations (L4), domain execution (L5), orchestration (L6), surface interfaces (L7), and compounding memory (L8). In most commercial categories, the competitive action in 2026 is playing out at L7 — the surface — where beautiful interfaces attract users but become commoditised quickly when the underlying model improves.
In legal and healthcare, the competitive action is happening at completely different layers. And understanding which layers are genuinely defensible in each vertical is the most important strategic question you can ask.
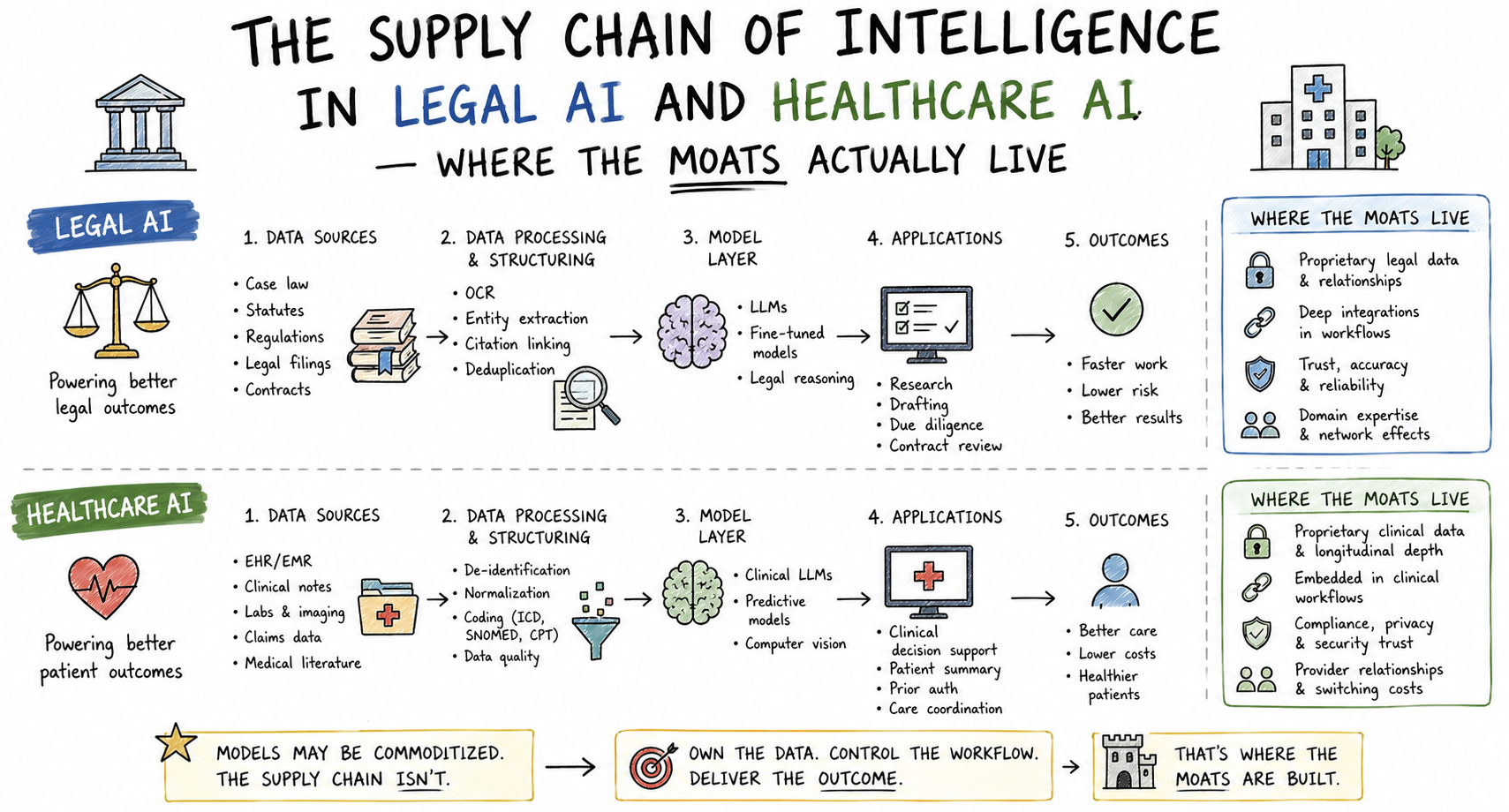
Part I: The Supply Chain of Intelligence in Legal AI
The Layer Map for Legal
Spend five minutes thinking about what a law firm actually produces, and the intelligence supply chain becomes visible.
A senior partner doesn’t just answer questions. They apply decades of case experience to a specific client matter, under a specific regulatory regime, in a jurisdiction with particular precedents, subject to attorney-client privilege, with professional liability on every word they write. That’s not a task you hand to a general-purpose chatbot. It’s a chain of specialized capabilities, each one operating inside tight constraints.
Here’s what the legal intelligence chain looks like, mapped to the framework:
L1b — Proprietary case law and matter data. The raw material. Licensed legal databases (LexisNexis, Westlaw), but more importantly, the internal matter history a firm accumulates over the years — the specific arguments that worked against a particular judge, the clause variations that survived a particular client’s procurement review, and the negotiating history with a particular counterparty. This data exists nowhere else. It can’t be scraped, purchased, or synthesized. It accumulates only through doing real legal work.
L3 — Compliance and trust gates. Attorney-client privilege is not a feature. It’s a legal doctrine that governs what an AI system is allowed to see, store, process, and transmit about client matters. Data privacy requirements, bar association ethics rules, and increasingly, procurement-level AI governance frameworks at major law firms create a multi-layered gate that any AI system must pass through before it touches client data. This isn’t friction. It’s a structural barrier that takes eighteen months to navigate and creates significant moat value for the companies that have already crossed it.
L5b — Legal reasoning scaffolds and decision frameworks. The craft of legal work — how to structure a contract argument, how to identify the controlling precedents in a circuit, and how to frame a discovery request in a way that survives a motion to compel — is deep domain knowledge that doesn’t exist in any foundation model. It has to be built from real practice, encoded in prompts and workflows, and output templates that reflect how actual lawyers actually work.
L8d — Institutional memory of matters. This is where the long-term value lives. A system that remembers what happened in the last deal with this counterparty, what arguments your firm made in similar matters, what this client’s risk tolerance has historically been — that’s not a feature you add after launch. It’s memory that accumulates through use, and it’s practically impossible for a new entrant to replicate once it’s established.
What Harvey Is Actually Building
Harvey’s $11 billion valuation is sometimes discussed as if it’s a bet on a legal chatbot. It isn’t. It’s a bet that Harvey will own multiple layers of the legal intelligence chain simultaneously.
Harvey’s iManage integration — which lets lawyers query firm documents and precedents directly through their document management system, without switching contexts — is not a product convenience. It’s an L4 access play that embeds Harvey into the workflow at the point where legal work actually happens. Switching away from Harvey doesn’t mean switching to a different AI tool. It means rebuilding the integration with your DMS, your prompt libraries, your internal knowledge base, and your governance controls. The switching cost is real and substantial.
The Memory feature Harvey launched in January 2026 — allowing AI to retain and apply past context, working styles, and best practices across engagements — is an explicit L8 play. Every case worked, every contract reviewed, and every preference noted adds to an institutional knowledge layer that becomes more valuable and harder to replicate as it grows. Harvey’s active file counts grew from 268,000 to 9.75 million in a single year — a 36x increase that signals deep integration into daily legal workflows, not just occasional use.
The LexisNexis partnership adds primary law and editorial authority – an L1b data layer that connects Harvey to licensed legal content that competitors without the same partnership can’t access at the same depth or with the same provenance guarantees.
Put it together: Harvey is building at L1b + L3 + L4 + L5b + L8d. That’s five layers. Not a chatbot. A supply chain.
Where the Legal AI Wrappers Will Break
The other side of the legal AI market is important to understand because it shows exactly what not building a supply chain looks like.
The commodity tools are falling because customers know they can replicate 90% of their value using Anthropic or OpenAI directly. The companies that built thin interfaces on top of generic models — without proprietary data, without compliance gate investments, without workflow integration, and without accumulated matter memory — are discovering that their product is one Claude or GPT release away from being free.
This pattern is structural, not incidental. Once foundation model providers enter a vertical directly, customers ask a simple question: Why am I paying a markup for a slightly customised interface when the underlying model is the only thing I’m actually paying for? The answer, if you haven’t built below L7, is ‘you’re not’.
Legal AI faces 18–24-month regulatory navigation timelines for enterprise deployment at serious firms. That timeline is a barrier for everyone — including incumbents expanding into the space. The companies that have already invested in crossing those compliance gates are structurally protected in ways that a better model doesn’t immediately overcome.
What to Build in Legal AI Right Now
If you’re a founder or product leader operating in the legal AI space, the supply chain lens produces three concrete strategic questions:
Where is your L1b? What data does your system access that a competitor using the same foundation model cannot? If the answer is “we use the same public legal databases”, you need to find your proprietary data layer. Firm-specific precedent databases, client negotiating histories, jurisdiction-specific ruling patterns — these are the L1b candidates worth building around.
What’s your L3 story? Compliance isn’t a late-stage concern. Law firms that handle matters for financial institutions, government clients, or cross-border mandates require AI vendors to clear procurement-level AI governance reviews before deployment. Building compliance infrastructure early doesn’t just protect you — it creates a moat that competitors who didn’t invest early can’t cross quickly.
What accumulates over time? The system you build in 2026 will be compared to your competitors not just on what it does today but on what it knows about each client’s history, preferences, and prior work. Design memory architecture into your product from the beginning, not as a feature you add in v3.
Part II: Where Healthcare AI Companies Can Build Moats
Why Healthcare Is Different — and Harder
Healthcare AI has all the same regulatory complexity as legal AI and adds a dimension that makes it categorically more demanding: stakes.
A legal AI system that produces a flawed contract clause creates liability exposure for a client. A healthcare AI system that misidentifies a drug interaction, misses a diagnostic signal, or generates a billing code that doesn’t reflect actual care delivered creates patient harm and potential criminal exposure. The error tolerance in healthcare AI isn’t low. In many applications, it approaches zero.
This shapes the entire intelligence supply chain for healthcare in ways that legal doesn’t fully mirror. Every layer has a healthcare-specific version, and the gatekeeping layer — L3 — is not just a compliance gate. In healthcare, L3 is the clinical safety infrastructure that determines whether a system can be deployed in patient-facing or clinical decision-support contexts at all.
The Layer Map for Healthcare
L1c/L1d — Behavioral and outcome data from actual clinical encounters. This is the most defensible data layer in healthcare, and it’s the one most AI companies building in the space don’t have. Claims data, EHR data, imaging data, genomic data — all of it is valuable, but the most defensible is outcome data: what actually happened to patients who received specific interventions, under specific clinical circumstances, at specific institutions. Tempus has spent a decade building this layer in oncology. Their multimodal dataset connecting genomics, imaging, clinical records, and outcomes is what makes their AI defensible — not their models.
L3a — Clinical compliance, safety, and regulatory gates. HIPAA is table stakes. The defensible L3 in healthcare includes FDA regulatory clearance for diagnostic AI, integration into clinical workflow governance frameworks, and the demonstrated clinical validation that allows a health system’s chief medical officer to stand behind the output. These gates take years to clear. Once cleared, they create barriers that a competing system with a better underlying model still has to spend years crossing.
L5a — Domain execution inside clinical workflows. This is where ambient scribing companies like Abridge and Nabla are competing fiercely, and it illustrates both the opportunity and the risk. Ambient scribing — AI that listens to a clinical encounter and generates documentation — solves a real problem. Clinician burnout from documentation is measurable, pervasive, and costly. The system that embeds itself inside the clinical encounter, understands the workflow, knows the EHR structure, and produces documentation that passes clinical review is doing real L5 work.
The risk is visible: Epic, Oracle Health, and athenahealth have all introduced their own ambient scribes and are building AI directly into their platforms. This is the L7 surface getting absorbed by the L4 access layer — the EHR platform below becoming the ambient scribe above. Companies whose only defensibility lies in the quality of their ambient scribing interface are exactly the companies that EHR platforms are threatening to absorb.
L8e — Learned world models for clinical reasoning. This is the frontier — and it’s what Nabla’s $1.03 billion partnership with AMI Labs is explicitly targeting. The distinction they’re drawing is important: probabilistic LLMs predict likely next tokens based on training data. They don’t model the causal relationships between clinical interventions and patient outcomes. A world model that genuinely understands why a specific beta-blocker combination poses risk for a patient with specific comorbidities is qualitatively different from a model that can describe that risk in fluent text. The companies building at L8e are playing a longer, harder, more capital-intensive game — but the defensibility of genuine clinical world models, once built and clinically validated, would be extraordinary.
The Tempus Playbook — Own the Data Nobody Else Can Buy
Tempus is the clearest example of what the Defensible Triangle — L1b + L5 + L8 — looks like when executed in healthcare over a decade.
They didn’t start with AI. They started with data. A decade of genomic sequencing partnerships with hospital systems like Northwestern Medicine built an L1b dataset of multimodal clinical data that no competitor can replicate by building a better model. The David AI system, now integrated directly into Northwestern’s EHR, is the L5 and L8 payoff on that data investment — a system that can deliver actionable insights in real time because it connects multiple data modalities that competitors simply don’t have.
Tempus’s M&A strategy follows the same supply chain logic: acquiring Arterys (imaging AI) and Paige (pathology AI) isn’t about buying technology. It’s about adding data modalities to a clinical intelligence chain that becomes more defensible with each addition. Health systems want to buy fewer, deeper systems rather than ten point solutions. Tempus is building the deep system.
The Ambient Scribing Trap
The ambient scribing market illustrates the L7 commoditization risk with unusual clarity.
AI scribes have been adopted by 92% of US health systems — a pace of adoption that, as Bessemer notes, makes the previous fifteen-year EHR rollout look glacial. The ROI is real: early adopters report 10–15% revenue capture improvements through better coding and documentation in the first year. Clinicians aren’t just accepting AI scribes — they’re demanding them.
But the clinical documentation AI market attracting this adoption is also the market most directly in the crosshairs of EHR platforms with near-universal distribution. When Epic, Oracle, and athenahealth build ambient scribing natively into platforms that already sit inside every clinical workflow, the question for standalone scribing companies becomes the same question that faced Jasper in legal writing: Why am I paying separately for this?
The companies surviving this consolidation pressure are the ones who understood this risk early and expanded beyond documentation before the EHRs arrived. Abridge partnering with Highmark Health to deploy AI for real-time prior authorization is the right move: it’s moving from a surface-layer documentation feature into L5 clinical workflow execution that the EHR can’t easily absorb. Nabla adding medical coding assistance and direct EHR command functionality is the same logic.
The ones who stayed at L7 — ambient scribing and nothing else — are in the most exposed position.
What to Build in Healthcare AI Right Now
If you’re building clinical AI, the first question is the same as in legal: where is your data layer that nobody else can access? Behavioral data from real clinical encounters, outcomes data from actual patient populations, and multimodal data that connects imaging, genomics, and clinical records are the L1b/L1c/L1d candidates worth protecting aggressively. A healthcare AI company with exclusive access to clinical imaging data has a structural advantage that persists even as underlying models improve.
Your L3 investment is your moat, not your cost. The instinct is to treat regulatory compliance and clinical validation as expenses to minimize. The strategic reality is that a system with FDA clearance, HIPAA-compliant infrastructure, and demonstrated clinical validation in peer-reviewed literature is sitting behind a gate that competitors without those credentials can’t cross for years. Treat compliance as a product, not overhead.
Design for the EHR reality. Ambient scribing is already becoming an EHR feature. If your product is adjacent to the EHR workflow, the question isn’t whether the EHR will compete with you. It’s which layers you can own that the EHR can’t absorb. L1 data the EHR doesn’t have, L5 domain execution for workflows the EHR doesn’t build, L8 memory that accumulates across encounters in ways the EHR’s generic patient record doesn’t — these are the directions that lead to durability.
The Pattern Across Both Verticals
Legal AI and healthcare AI look different on the surface. Law firms and hospitals have entirely different cultures, workflows, buyers, and risk tolerances. The specific layer strategies that work in each are genuinely distinct.
But the underlying supply chain logic is the same across both.
Regulation is a moat, not a burden. Every compliance requirement, approval pathway, and governance framework that makes your life harder as a founder is making your competitors’ lives equally hard — but you’ve already paid the cost. Once you’re inside the regulatory gate, you’re inside. Competitors who haven’t crossed it yet are on the wrong side of a wall that buys you time.
Data that accumulates through use is irreplaceable. The most defensible position in both verticals isn’t the best model. It’s the data that a competitor using the same model couldn’t access. Legal matter history. Clinical outcome data. Institutional knowledge of specific client or patient populations. These datasets don’t exist in any public repository. They exist only inside organizations that have been doing the real work for years — and they’re available only to the AI systems those organizations trust enough to embed.
Memory is the compounding layer. In both verticals, the switching cost that matters isn’t losing a tool. It’s losing the accumulated understanding of your specific context — your firm’s approach to this type of deal, your health system’s clinical protocols, and your patient population’s outcome patterns. Once that memory is embedded in an AI system, the cost of starting over with a competitor isn’t the price of a new subscription. It’s rebuilding years of contextual intelligence from scratch.
This is the insight at the center of the Supply Chain of Intelligence framework: value doesn’t accrue at the surface, where users interact with AI. It accrues in the chain beneath – in the data nobody else can buy, the compliance gates nobody else has crossed, the workflows nobody else has embedded, and the memory nobody else has accumulated.
The companies building at those layers, in legal and healthcare and every regulated vertical, are building the durable AI businesses of the next decade.
The ones building shiny surfaces on top of generic models are building features.
Anand Arivukkarasu is an ex-Meta (Instagram) product leader and the creator of the Supply Chain of Intelligence™ — a 10-layer defensibility map for AI companies across verticals. All 24 case studies, per-layer deep dives, and the full framework are free at supplychainofai.com.