The Orchestration Trap Nobody Warned You About
Interest in multi-agent AI didn’t creep up on the industry. Multi-agent system inquiries surged 1,445% between Q1 2024 and Q2 2025. The momentum is real and justified — enterprises deploying properly architected multi-agent systems report meaningful gains in task completion speed and accuracy on complex workflows versus single-agent implementations.
But here’s the uncomfortable number sitting next to all that enthusiasm: Gartner predicted in January 2026 that more than 60% of early agentic orchestration implementations will fail to meet performance or cost expectations by 2030, because enterprises will underestimate the integration, governance, and talent required to make digital workforces reliable at scale.
The reason these predictions coexist – massive adoption and massive failure rate – is that people are confusing two very different things: deploying agents and orchestrating them.
Deploying an agent is a software problem. You pick a framework, wire it to a model, connect it to a tool, and ship it. Dozens of good solutions exist. The frameworks are mature. The models are capable.
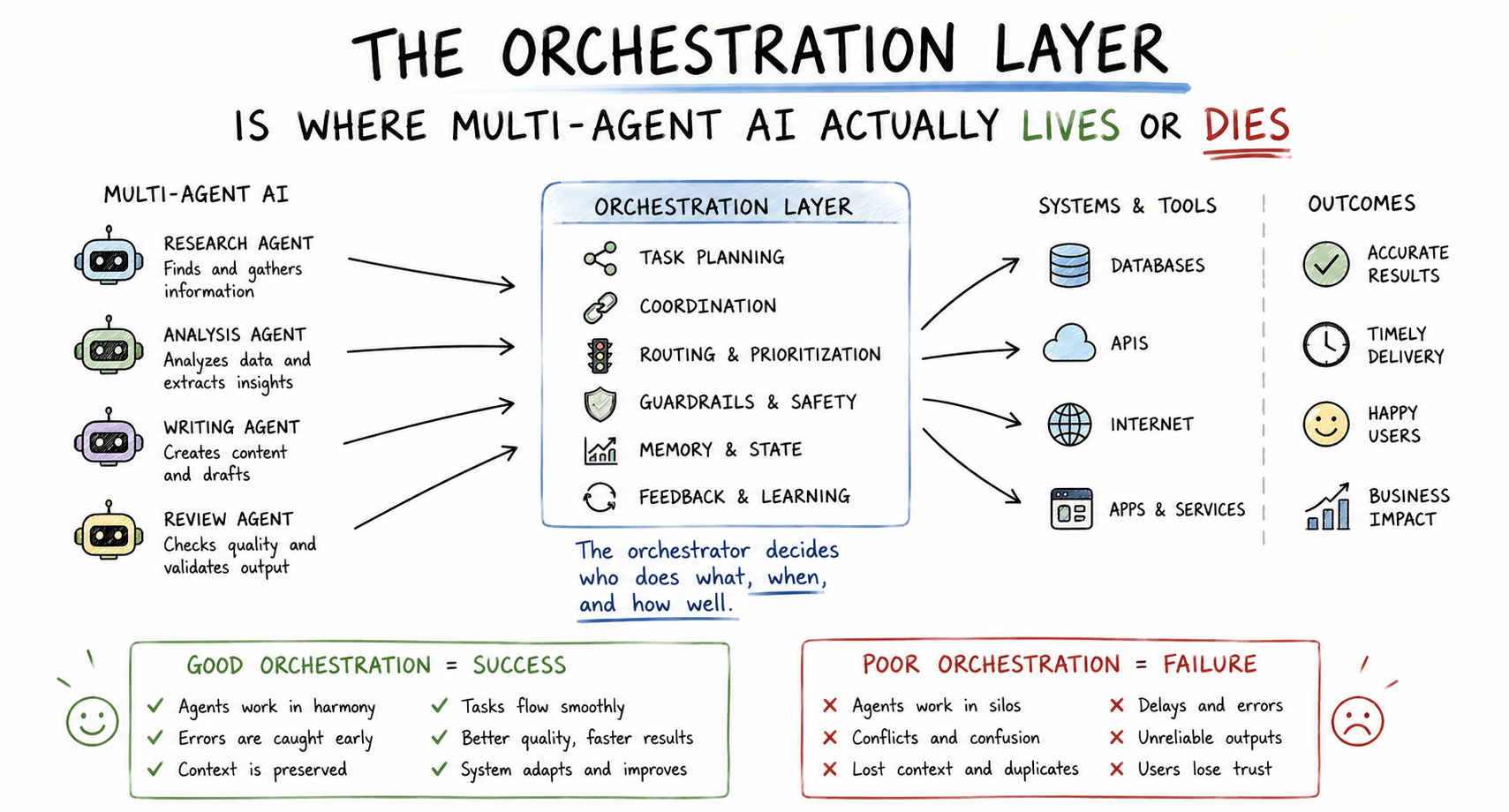
Orchestrating agents — getting multiple agents to coordinate reliably, pass context accurately, handle failures gracefully, know when to escalate to a human, and produce outcomes you can actually audit — is an entirely different discipline. And most organisations are treating it like it’s the same problem.
The MAST Failure Taxonomy, validated across 1,600+ execution traces at NeurIPS 2025, maps failures across three root categories: specification problems at 41.77% of failures, coordination breakdowns, and verification gaps. Most “agent failures” aren’t model failures at all — they’re orchestration and context-transfer failures at the handoff points between agents.
Said plainly: the model is rarely what breaks. The handoff is what breaks.
Why This Is a Supply Chain Problem
This is where the mental model most teams are using leads them astray.
The dominant way people think about multi-agent systems is as a workforce. You have a manager agent. You have specialist agents. You assign tasks, the specialists do the work, and the results come back up the chain. It’s an org chart built in software. And like most org charts, the coordination costs are invisible until something goes wrong – at which point they become the only thing you can see.
There’s a better mental model: a supply chain.
In a physical supply chain, the product passes through a series of handoff points — supplier to warehouse to distribution center to store to customer. Each handoff is a potential point of failure. Contamination can enter. Quality can degrade. Information can be lost. Inventory can sit unaccounted for. The discipline of supply chain management exists precisely because those handoffs don’t manage themselves. You need visibility into what’s moving where. You need quality gates at each transfer. You need clear ownership of each stage. You need a system that surfaces problems at the point where they occur rather than three stages downstream when the damage is already done.
Multi-agent AI systems have the same structure — and the same failure modes. Intelligence flows through a chain of agents, each one taking in what the previous one produced and passing forward something transformed. Every handoff is a potential point of degradation. Context gets compressed. Errors accumulate. Decisions made on stale information propagate forward. And by the time a wrong answer surfaces at the output, the root cause is buried three agents deep in a conversation log nobody is reading.
This is the core insight behind the L6 Orchestration layer in the Supply Chain of Intelligence™ framework — the layer that sits between domain execution (L5) and the user-facing surface (L7). In the 10-layer map of the generative AI stack, L6 is where agent loops run, where context and state are managed, where role routing and task decomposition happen, where human-in-the-loop checkpoints get defined, and where runtime assurance operates. Context inconsistency — not pattern choice — is the primary reason multi-agent orchestration fails in production. Agent memory is transient; the shared context layer is the persistent state store across multi-agent pipeline steps.
L6 is the logistics infrastructure of intelligence. And just like physical logistics, it’s invisible when it works and catastrophic when it doesn’t.
What the Handoff Problem Actually Looks Like
Let me be specific, because the failure modes in orchestration are concrete and recurring.
The lossy summary problem. When Agent A completes its work and passes to Agent B, it needs to communicate what happened. If that communication is a natural language summary — which it usually is — information gets lost in compression. Agent B reasons on an approximation of what Agent A knew. Agent C reasons on an approximation of Agent B’s approximation. By step five or six in a complex workflow, the original context is a ghost of itself, and the agent at the end of the chain is making decisions on information that barely resembles what the system started with. Context loss compounds with every transfer — either you pass full context, which is expensive and eventually exceeds context windows, or you summarize, which is lossy, and accumulated summarisation errors degrade output quality across the chain.
The infinite handoff loop. Agent A passes to B, B passes to C, C passes back to A. Each agent keeps replanning because nobody owns the task. This is the number one failure mode in production orchestration systems. It happens when task ownership isn’t explicitly assigned, when success criteria are ambiguous, or when the orchestration logic doesn’t have a clear termination condition. The agents are all working. The system is producing nothing.
The stale state problem. In a multi-agent system operating across time — which is most real enterprise deployments — information retrieved at step one may be outdated by step four. An agent that checks inventory levels and then hands off to a procurement agent may be handing off a number that changed while the orchestration was running. Without a shared state layer that maintains a single source of truth across the agent chain, decisions get made on information that is technically accurate to the moment it was retrieved and practically wrong by the time it matters.
The silent error amplification problem. Silent errors amplified across agent pipelines are more dangerous than surface hallucinations, requiring intervention before execution rather than after. A small error in an early agent — a slightly wrong classification, a subtly incorrect extraction — doesn’t surface immediately. It gets passed forward as valid input, acted upon by subsequent agents, compounded by their processing, and only becomes visible when it manifests as a wrong output at the end. Tracing back through a six-agent chain to find the original error is a genuinely hard debugging problem, especially when the agents’ reasoning processes aren’t logged at sufficient fidelity.
The Protocols Are Finally Catching Up
One genuinely good thing happened in the past eighteen months: the infrastructure layer for agent communication finally got real standards.
Model Context Protocol (MCP), launched by Anthropic in November 2024, and Agent-to-Agent (A2A) protocol, launched by Google in April 2025, form complementary infrastructure. MCP is vertical — how an agent discovers and invokes tools, resources, and data. A2A is horizontal — how agents discover and communicate with each other. The analogy that holds: MCP is USB-C for AI agents, A2A is HTTP for the agentic web.
With 5,000+ MCP servers now available and Gartner projecting 75% of API gateway vendors will add MCP features by 2026, this has moved from optional to foundational. A2A was transferred to the Linux Foundation in June 2025, signaling that the industry has aligned around it as an open standard rather than a proprietary protocol.
What this means practically: the plumbing problem of agent communication is largely solved. Agents can now discover each other, invoke each other’s capabilities, and transfer tasks through standardized interfaces. This separation is more consequential than it first appears — without it, agent systems collapse into distributed monoliths characterized by embedded business logic, hardcoded integrations, tight workflow coupling, and limited extensibility.
But solving the plumbing problem hasn’t solved the orchestration problem. Protocols tell you how agents talk to each other. They don’t tell you what to do when an agent says something wrong. They don’t define the quality gates between stages. They don’t manage the shared context that persists state across a long-running workflow. They don’t tell you when to escalate to a human versus let the system proceed autonomously. Those are orchestration decisions, and they require architecture that most teams haven’t built yet.
The Supply Chain Mindset in Practice
The organizations that are getting multi-agent orchestration right in production are, consciously or not, applying supply chain logic to their agent architecture. Here’s what that looks like in practice.
Define the chain before you build the agents. The most common mistake is starting with the agents and then figuring out how they connect. The right approach is the reverse. Map the flow of information through your system — what enters, what transforms, what gets passed forward, what must be preserved at each handoff, what constitutes a successful output. Only then do you design the agents that handle each stage. This is exactly how supply chain design works: you map the flow first, then you resource each node.
Put quality gates at every handoff. In a physical supply chain, no serious operation passes goods from one stage to the next without some form of quality check. The pharmaceutical industry doesn’t ship active ingredients to formulators without an assay. The semiconductor industry doesn’t pass wafers to the next fabrication step without electrical testing. Your agent pipelines need the same discipline. Production systems need evaluation agents that check outputs before they’re passed downstream. Error recovery — not just error handling — is what separates prototypes from production systems. This is L3 gatekeeping logic applied inside the orchestration layer.
Maintain a shared state layer, not just agent memory. Individual agent memory — what a single agent knows about the current conversation — is not the same as shared state across an orchestration. The former resets with each new agent invocation. The latter preserves the ground truth of what has happened across the entire workflow. The shared context layer is the persistent state store across multi-agent pipeline steps — the thing that prevents agents downstream from making decisions based on information that was accurate three steps ago and is wrong now. Building this layer explicitly, rather than assuming agents will maintain coherent shared understanding through natural language summaries, is one of the highest-leverage architectural decisions in multi-agent systems.
Design human-in-the-loop as architecture, not an afterthought. The human oversight model is evolving along a spectrum: humans in the loop (approving every decision), humans on the loop (monitoring with intervention capability), and humans out of the loop (fully autonomous). Advanced organizations in 2026 are shifting to “on the loop” — maintaining oversight without bottlenecking agent operations. The keyword is “shifting” — this isn’t a toggle you flip at deployment. It’s an architectural decision that determines which actions agents can take autonomously, which ones require human confirmation, and what the escalation path looks like when an agent hits a situation outside its defined operating envelope.
Build for observability from day one. You cannot manage what you cannot see. In a supply chain, you have tracking at every node — where is each unit, what state is it in, and when did it move? Your agent pipelines need the same. Decision logging — why did the agent choose this option? — replay capability to reconstruct and debug a failed run, and kill switches that enforce hard boundaries on autonomous behavior are not optional features. They’re the operational infrastructure that separates a production system from a demo.
Where Orchestration Becomes Defensible
Here’s the strategic point that goes beyond engineering.
Most of the conversation about orchestration is tactical — how do you get multi-agent systems to work reliably? That’s a real and important problem. But there’s a second-order question that product leaders and founders should be asking: if you build orchestration that works, what have you actually built?
The answer, from the lens of the Supply Chain of Intelligence™ framework: you’ve built at L6, and L6 is one of the structurally interesting layers in the AI stack.
Here’s why. The orchestration layer accumulates something over time that individual agents don’t: workflow knowledge. The routing decisions, the escalation patterns, the quality thresholds, the handoff protocols that actually work for your specific domain — none of that is in any foundation model. It’s built from running real workflows in your specific context, observing what fails, and encoding the corrections. Over time, a mature orchestration layer becomes a representation of how your domain actually works — encoded not in an agent’s weights but in the architecture of how agents are coordinated.
That’s not easy to copy. It’s not a model. It’s not a UI. It’s operational intelligence embedded in orchestration design. Companies like Sierra have built significant defensibility at this layer — the operating playbooks and orchestration logic that govern their customer service agents encode years of real interaction patterns in ways that a competitor starting from scratch cannot replicate from a model alone.
Vendor lock-in in 2026 persists at the orchestration and workflow layers specifically — not at the model layer, which is increasingly commoditized, and not at the surface layer, which is easily replicated. The orchestration layer is where the real stickiness lives.
This is the supply chain mindset applied to strategic positioning: the logistics layer — unglamorous, complex, invisible to end users — is often where the most durable competitive advantage accumulates.
What This Means If You’re Building Now
A few concrete things worth taking seriously.
Don’t scale agents before you’ve proven handoffs. The organisations that succeed with agentic AI start with one agent, one workflow, one specific measurable outcome. They prove it works. Then they expand. The orchestration complexity multiplies the failure surface area exponentially — deploying five agents before a single agent works reliably in production is almost always a mistake.
Treat your orchestration layer as a product, not plumbing. Most teams assign orchestration to whoever has time between building the “real” agents. The teams getting this right assign dedicated owners to the orchestration layer, treat it as a distinct product surface with its own roadmap, and invest in its observability and reliability the way they’d invest in any production infrastructure.
Your shared context architecture is a strategic asset. The design decisions you make about how state is maintained, what gets preserved across agent handoffs, and how context degrades gracefully when windows are exceeded aren’t just engineering decisions. They’re the foundation of the workflow knowledge that will differentiate your system from a generic multi-agent scaffold twelve months from now.
The gap between pilot and production is an orchestration gap. When a team says, “We proved it in the demo but can’t get it to work in production,” they almost always mean that the orchestration assumptions that held in a controlled environment broke under real-world conditions – variable input quality, unexpected agent failure, latency spikes, edge cases in task routing. Treating that gap as a model problem leads to the wrong solutions. Treating it as an orchestration problem leads to the right ones.
The Quiet Layer Nobody Is Talking About Enough
The current conversation about AI in enterprise is overwhelmingly about two layers: the model (which foundation model are you using, how do you fine-tune it, what are its capabilities?) and the surface (what does the interface look like, how do users interact with it, what’s the UX).
The orchestration layer sits between them, unglamorous, complex, and largely invisible to anyone who isn’t trying to run a multi-agent system in production. But as the number of deployed agents grows from the current tens of millions toward the hundreds of millions projected by 2028, orchestration is going to be the defining technical and strategic challenge of the agentic era.
The companies that figure out how to make intelligence flow reliably through a chain of agents — with the right quality gates, the right shared state, the right human oversight, and the right observability — are going to look, in hindsight, a lot like the companies that figured out supply chain management in the manufacturing era. Not the most visible companies. Not the companies with the best product demos. The companies with the most reliable operations. And in industries where reliability is the product, that’s the only competitive advantage that actually compounds.
That’s the supply chain mindset. And it’s the right lens for everything happening at L6 right now.
Anand Arivukkarasu is an Ex-Meta (Instagram) Product Leader and the creator of the Supply Chain of Intelligence™ — a 10-layer defensibility map for the generative AI stack. Explore the full framework, case studies, and per-layer deep dives at supplychainofai.com.